A Beginner’s Guide to Site Reliability Engineering: Significance, Best Practices, Core Principles, and Tools

Every time you stream a movie on Netflix or hit "send" on a banking app, you’re interacting with an invisible architecture. We take it for granted that these systems respond instantly and reliably, but they don’t stay that way by accident.
Behind that seamless experience is a discipline called Site Reliability Engineering (SRE).
SRE emerged from Google in the early 2000s when they realized that infrastructure was becoming too complex for manual management. They stopped treating "keeping the lights on" as a manual chore and started treating it as a software engineering problem. The goal was simple: Build systems that manage themselves so that engineers don't have to act as human routers for every alert.
Site reliability engineering (SRE) is the practice of using software tools to automate IT infrastructure tasks such as application monitoring and system management. Companies use SRE to ensure their software applications remain reliable amidst frequent updates from the development teams.
DON'T MISS: How You Can Build Incident Management Inside Jira For FreeWhy is Site Reliability Engineering Important?
In today’s digital economy, the reliability of software systems directly impacts business success. When applications crash, slow down, or become unavailable, the consequences extend far beyond technical inconvenience. They affect revenue, customer trust, and competitive advantage
Software systems are increasingly complex. Modern applications consist of numerous interconnected services, third-party integrations, and infrastructure components spread across multiple data centers or cloud regions. As developers continuously push updates to add features and fix bugs, they can inadvertently introduce instability. A single code change might work perfectly in isolation but cause cascading failures when it interacts with the broader system under real-world conditions.
Without structured approaches to managing this complexity, organizations face a dilemma: move fast and risk breaking things, or move slowly and lose market competitiveness.
Site Reliability Engineering addresses this challenge systematically by:
- Bringing the operations and development divide: Traditionally, development and operations teams have competing priorities. Developers want to ship features quickly; operations teams want stability. This tension often creates friction, finger-pointing, and inefficiency. SRE resolves this by establishing shared objectives and a common language around reliability. This transforms an adversarial relationship into a collaborative partnership.
- Protecting the customer experience: Users expect applications to work flawlessly, regardless of how many people are using them simultaneously or what’s happening behind the scenes. SRE practices ensure that software errors, infrastructure failures, and deployment issues don’t degrade the customer experience. By automating testing, deployment, and monitoring, SRE teams catch problems before users encounter them. When issues do occur, automated systems can detect and often resolve them faster than any human could manually intervene.
- Enabling Sustainable Growth: As companies grow, doing everything manually no longer works. If teams must watch every deployment, investigate every alert, and manually update every setting, the operations team quickly becomes overwhelmed. SRE focuses on automation and reducing repetitive work, so systems can scale without the need to constantly add more people. This makes growth easier and more cost-effective.
- Providing Predictability in a Highly Unpredictable Environment: Business leaders need to understand and plan for operational risks. SRE provides quantitative frameworks: service level objectives, error budgets, and availability targets that make reliability measurable and predictable. Organizations can estimate the cost and impact of downtime, make informed decisions about acceptable risk levels, and communicate clearly with stakeholders about service expectations. This transforms reliability from a vague hope into a managed business outcome.
- Reducing Firefighting, Increases Innovation: When the operations teams are always busy fixing issues and doing manual work, they have no time to improve how systems run. A Site Reliability Engineering best practice principle encourages limiting operational work so engineers can spend time building better tools, improving automation, and fixing root causes. This creates a positive cycle: better automation reduces incidents, which frees up even more time to improve the system further.
In essence, Site Reliability Engineering is important because it provides a structured, scalable, and sustainable approach to reliability in an era where software systems are too complex for manual management and where downtime carries costs that businesses simply cannot afford.
Key Principles of Site Reliability Engineering
Now that we've explained what site reliability engineering is and its importance to an organization, let's look at the foundational principles that guide decision-making and daily actions.
- Reliability is a Feature, not an Afterthought: In SRE, reliability isn’t something you worry about after building your application. It’s designed into the system from the beginning, just like any other feature. A fast app that crashes often is less valuable than a simpler app that works consistently. This means reliability is given the same priority, planning, and resources as new features.
- Embrace Risk, Perfection Isn’t the Goal: This might sound counterintuitive for a role focused on reliability, but SREs understand that aiming for 100% uptime is both impossible and counterproductive. Every system will eventually fail, and the cost of trying to prevent every possible failure far outweighs the benefits. Instead, SREs determine an acceptable level of reliability (like 99.9% uptime) and use that as a guide. This frees teams to innovate and ship features rather than endlessly pursuing unattainable perfection.
- Eliminate Toil Through Automation: In SRE, "Toil" is the manual glue that keeps a system running but doesn't make it any better. It’s the repetitive, soul-crushing work—like manually clearing disk space or restarting a service—that grows every time you add a new user. If you're doing the same manual task twice a week, it’s not a task; it’s a bug in your process. SREs don't just "do" the work; they build systems to kill the work.
- Measure Everything and Let Data Drive Decisions: SREs don’t rely on gut feelings or assumptions. They measure system performance, user experience, and reliability using concrete metrics. Every decision, whether to roll back a deployment, how much risk to take with a new feature, or where to invest engineering effort, should be based on data. This principle transforms reliability from a vague goal into something quantifiable and manageable.
- Failures are Learning Opportunities, not Reasons for Blame: When systems fail (and they will), a part of SREs called incident management, focuses on understanding what went wrong and how to prevent similar issues in the future, not on finding someone to blame. This creates a culture where people feel safe reporting problems early and sharing knowledge about mistakes. The result is organizations that become stronger and more resilient with each incident rather than hiding problems or repeating the same failures.
What are Site Reliability Engineering Best Practices?
Below are the specific techniques and methods that SRE teams use to turn the key principles into reality.
- Define What “Reliable” Means: Before you can improve reliability, you need to define what it means.
- Service Level Indicators (SLI) are the specific metrics you measure. Things like the “percentage of requests that complete successfully” or “percentage of requests that respond within 200 milliseconds.”
- Service Level Objectives (SLO) are your targets for those metrics, for example, “99.9% of requests should complete successfully.”
- This practice transforms reliability from a vague aspiration into something concrete you can track and improve. When you know your SLO is 99.9% and you’re currently at 85.5%, you know exactly where you stand and what needs attention.
- Use Error Budgets to Balance Speed and Stability: An Error Budget isn't just a number; it’s a social contract. It defines exactly how much "unreliability" the business is willing to tolerate. For example, if your target is 99.9% uptime, you have a "budget" of 43 minutes of downtime per month. This turns the adversarial relationship between Developers (who want to ship) and SREs (who want stability) into a shared, data-driven decision. If you have 30 minutes of budget left, you can take risks and ship fast. If you’ve used up 42 minutes, the "cool new features" stop, and the focus shifts entirely to reliability. No arguments, just data.
- Practice Chaos Engineering: Rather than waiting for failures to happen in production, some SRE teams deliberately introduce controlled failures in their systems to test resilience. This might mean randomly terminating servers, introducing network delays, or simulating database failures, all in a controlled way. The practice helps identify weaknesses before they cause real problems.
- Conduct Blameless Post-Mortem After Incidents: When something goes wrong, an outage, a performance degradation, or a security incident, SRE teams conduct a structured review afterwards. The blameless part is crucial: the goal is to understand what happened and how to prevent it, not to punish anyone. A good postmortem document contains the following. These documents become valuable organizational knowledge, helping the entire team learn from each incident.
- Implement Comprehensive Monitoring and Alerting: You can’t fix problems you don’t know about, and you can’t understand your system’s behaviour without visibility into it. SRE teams implement monitoring that tracks:
- System health metrics (CPU, memory, disk usage).
- Application performance (response times, error rates, throughput).
- Business metrics (user signups, transactions completed).
- Dependencies (databases, external APIs, other services).
- Continuously Review and Improve: Site Reliability Engineering isn’t a one-time implementation; it’s an ongoing practice. Regular reviews of SLOs, postmortem trends, toil levels, and system architecture help teams identify areas for improvement and ensure they’re focusing on the right priorities.
What is Monitoring in Site Reliability Engineering?
Monitoring is the practice of continuously collecting, tracking, and analyzing data about your systems to understand their current state and behavior. Think of it as your system’s vital signs, like a doctor checking your heart rate, blood pressure, and temperature to understand your health.
You can’t manage what you can’t see. Without monitoring, you’re essentially flying blind; you won’t know when systems are failing, degrading, or about to have problems until users start complaining. By the time that happens, the damage to user experience and business reputation may already be done.
What is Observability in Site Reliability Engineering?
While monitoring tells you that something is wrong, observability helps you understand why it’s wrong and how to fix it.
Observability is the ability to understand a system's internal state from the data it produces. It’s about answering questions you didn’t know to ask in advance. Unlike monitoring, which tracks known problems with predefined metrics, observability helps you investigate novel issues and understand complex system behaviors.
DevOps vs SRE
DevOps is a cultural philosophy and set of practices that emphasizes collaboration between software development (Dev) and IT operations (Ops) teams to deliver software faster and more reliably.
Traditionally, development and operations worked in silos: developers built new features and wanted to release them quickly, while operations managed production systems and wanted stability, often resisting frequent changes. This created friction, slow releases, and a “throw it over the wall” mentality where developers handed off code to operations without ongoing collaboration.
DevOps and SRE both aim to improve collaboration, automation, and software reliability, but they differ in structure and execution. DevOps defines the what (collaboration, automation, faster delivery). SRE defines how (engineering practices and quantitative reliability management). DevOps is broad and flexible, while SRE is focused and prescriptive, with a dedicated role and formal mechanisms for managing reliability at scale.
What are the Common Site Reliability Engineering Tools?
Site reliability engineering (SRE) teams use different types of tools to facilitate monitoring, observation, and incident response.
- Monitoring & Alerting: Track system health and notify teams when something goes wrong, with tools like Datadog, New Relic, and Grafana.
- Logging: Collect and search application and system logs to understand what happened during issues, with tools like ELK Stack (Elasticsearch, Logstash, Kibana) and Splunk.
- Configuration Management: Automate server and system configuration to keep environments consistent, with tools like Ansible, Chef, and Puppet.
- Incident Management: Manage on-call schedules, alerts, and incident response workflows, with Phoenix Incidents.

The Bottom Line: Where SRE Meets Reality
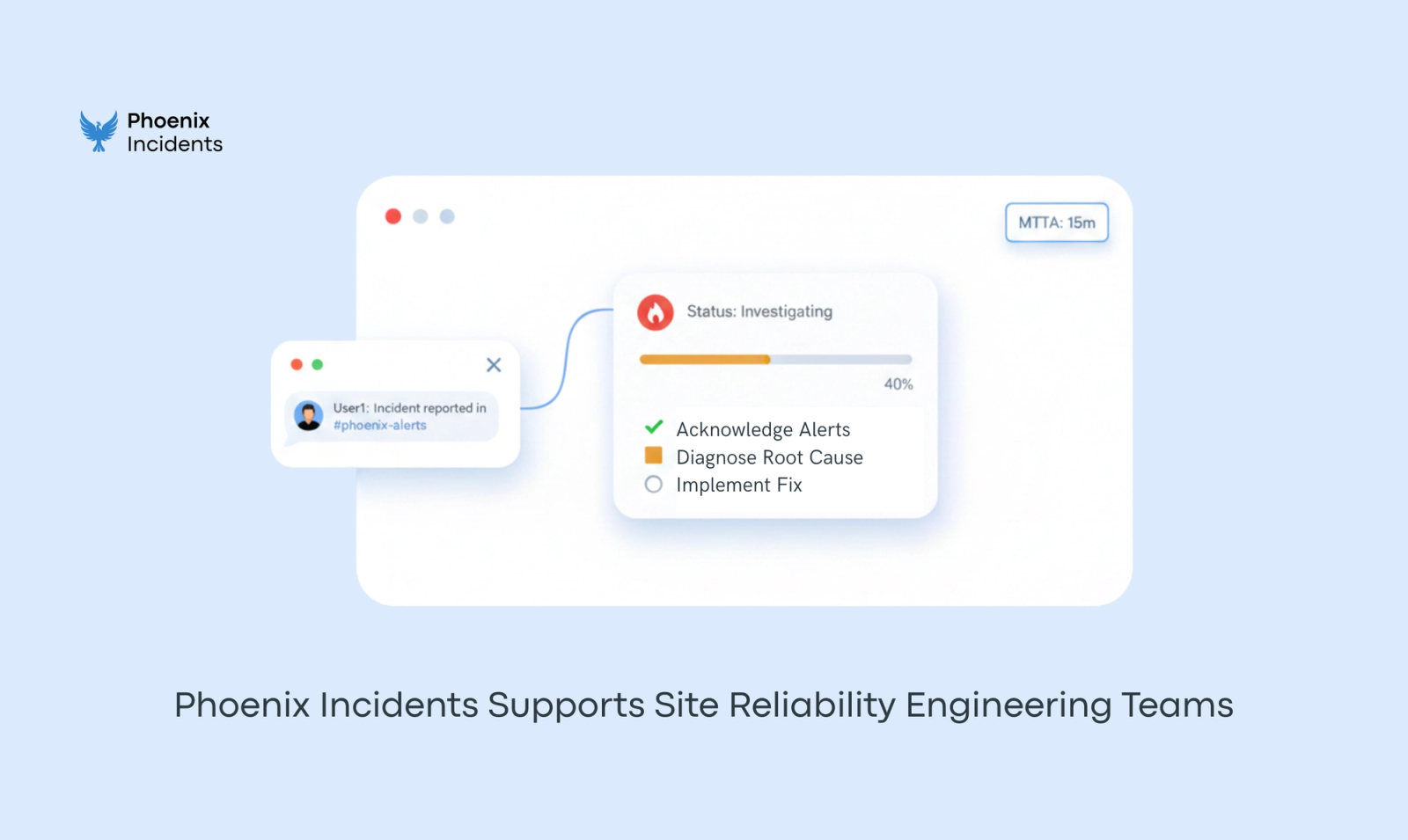
Most Site Reliability Engineering guides explain what "good" looks like on a whiteboard. The harder part is making it happen during a real incident, when context is fragmented and attention is scarce. Many teams quietly struggle, not because they lack monitoring, but because incident coordination lives in the cracks between their tools.
Phoenix Incidents exists to fill that gap. It removes the "social gamble" of early escalation, coordinates the response directly inside Slack and Jira, and enforces a clear process when pressure is highest. After resolution, it ensures that post-incident reviews result in concrete, tracked action items—not just "zombie" tickets that sit in a backlog.
For leaders, the system turns raw incident activity into usable signals—like MTTA, SLA performance, and recurring themes—so reliability becomes visible and improvable, rather than a vague hope.
Phoenix Incidents does not replace your core stack:
- Monitoring or observability tools: You still need to see why things are breaking.
- Paging platforms: You still need to wake the right people up.
- Communication tools: You still need to talk to your team.
Instead, we provide the connective tissue where human coordination happens. Detection tells you something is wrong. Phoenix Incidents helps your team respond, learn, and improve consistently. For SRE teams, that consistency is the difference between reliability as a theory and reliability as a lived reality.