How to Use Post-Incident Review to Improve Team Performance in Handling Incidents


A post-incident review (sometimes called a root cause analysis) is where engineering teams decide whether an outage becomes a one-off disruption or a recurring problem. Yet as important as this is, many teams rush through reviews, skip them entirely, or treat them as a compliance checkbox. And a few months later, you’re responding to a version of the same outage.
This article focuses on how to make better choices during and after a post-incident review, what to examine, what to document, and what to change. We’ll look at a practical post-incident review process that works inside the tools engineers already use, especially Jira and Slack, without adding procedural overhead or unrealistic promises.
What is a Post Incident Review (PIR)
Often referred to as a post-mortem or root cause analysis (RCA), a post-incident review is a structured look at what went wrong during a production incident, done after the problem is fixed. Its purpose is to understand what happened, why it happened, and what should change to reduce future risk.
A PIR is not a blame game exercise or a long, excessive document. A strong post-incident review process balances rigor with empathy and speed.
What Makes a Post-Incident Review Useful
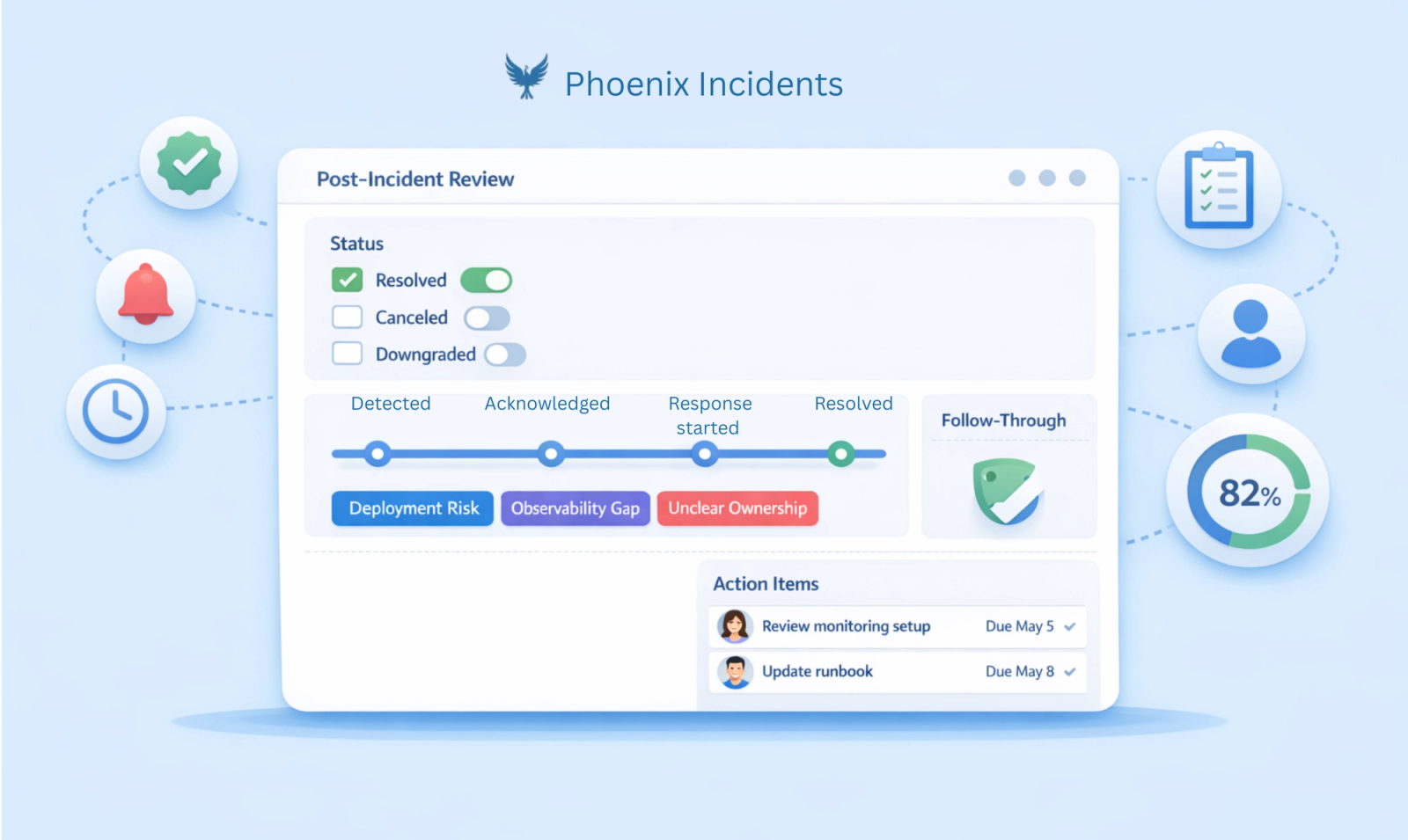
- Confirm incident status (including cancelled incidents): A strong post-incident review process starts by explicitly confirming how the incident ended, including whether it was resolved or cancelled. Many teams overlook explicitly examining cancelled incidents entirely, even though they often provide valuable learning.
- Identifying contributing themes: After the timeline is clear, the post-incident review should focus on identifying contributing themes rather than searching for a single root cause. Most serious incidents emerge from a combination of technical and organizational factors rather than one isolated failure.
- Define action items: An effective post-incident review produces a small number of action items that represent real commitments to reduce future risk. These action items should be clearly scoped, assigned to a specific owner, and tied to a realistic timeframe. When reviews generate too many action items, they become noise and follow-through almost always suffers.
- Enforce follow-through: The final step in the post-incident review process is ensuring that action items do not become new tombstones in the backlog graveyard. Teams need ongoing visibility into which action items are overdue, which contributing themes continue to recur, and whether previous decisions are actually reducing operational chaos. Without enforcement and visibility, post-incident reviews become a rote exercise rather than drivers of change.
Why Good PIRs Make the Next Incident Easier
The real value of a post-incident review is not in the document it produces but in how it changes team behavior during the next incident. When done consistently and well, post-incident reviews create a feedback loop that directly improves response speed, reduces confusion, and builds organizational muscle memory for handling production issues.
1. Faster Response Times Through Pattern Recognition
Teams that consistently review incidents start to recognize patterns in how problems unfold. When engineers see the same contributing themes appear across multiple post-incident reviews, they know exactly where bottlenecks exist. This pattern recognition translates directly into faster response during live incidents.
2. Reduced Repeat Incidents Through Action Item Follow-Through
The strongest correlation between post-incident reviews and improved team performance comes from action item completion. When teams define specific, scoped mitigations during a PIR and then actually implement them, they prevent entire classes of incidents from recurring. This is not theoretical. Teams that track action item completion rates alongside incident frequency can see the direct relationship: higher follow-through correlates with fewer repeat incidents.
3. Clearer Communication and Coordination Under Pressure
Post-incident reviews improve how teams communicate during live incidents by making communication breakdowns visible and addressable. When timeline reconstruction shows that stakeholders were not updated for 45 minutes during a critical outage, or that three engineers were working on the same fix without knowing it, teams can adjust their incident response protocols. They establish clearer update cadences, designate incident commanders, or implement better status broadcasting in Slack.
4. Measurable Outcomes of Consistent Post-Incident Reviews
The biggest payoff from good post-incident reviews shows up in MTTR (mean time to resolve).
When teams fix the coordination, ownership, and knowledge gaps that slowed them down last time, resolution gets faster the next time.
MTTD (mean time to detection) and MTTA (mean time to acknowledgement) improve too — but only when post-incident reviews explicitly identify detection gaps or hesitation in escalation and actually follow through on fixing them. When teams tune alerts, clarify escalation criteria, and remove fear around raising incidents, issues get noticed and acknowledged sooner as well.
5. Higher Team Confidence
Engineers who see their feedback from post-incident reviews translated into real process improvements feel more capable and less stressed during incidents.
These outcomes do not happen automatically. They require consistent execution of the post-incident review process, genuine follow-through on action items, and organizational commitment to treating incidents as learning opportunities rather than blame events.
Why This Gets Easier the More You Do It
The longer a team practices structured post-incident reviews, the more valuable each review becomes. Early reviews often uncover obvious gaps, such as missing monitoring or unclear on-call procedures. As those foundational issues are addressed, later reviews reveal more subtle improvements in team coordination, cross-functional communication, and architectural resilience.
This compounding effect means that teams should view post-incident reviews as a long-term investment in operational excellence rather than a per-incident compliance task. The team that conducts their 50th post-incident review is fundamentally more capable than they were at their first, not because individual engineers are smarter, but because the organization has systematically learned from every incident and applied those lessons to how they operate.
How to Run a Post Incident Review
Running a post-incident review often fails not because teams lack discipline, but because critical context is scattered across tools. Incident response unfolds in real time, yet the review happens later, when details have faded, and information is fragmented.
For teams that use Jira, a post-incident review works best when Jira is treated as the system of record rather than the place where the entire story must be reconstructed. Jira excels at capturing ownership, action items, and durable outcomes, but it struggles to reflect the real-time decision-making that happens during an incident. Teams run into trouble when they expect Jira alone to carry the full weight of the post incident review process.
Context is lost when Slack discussions, status updates, and coordination decisions are manually summarized days later. This gap leads to shallow reviews, incomplete timelines, and action items that don’t fully address what actually slowed the team down. To avoid losing context, effective teams focus on three principles during a post-incident review:
- Preserve real-time discussion rather than rewriting it from memory
- Keep the review closely connected to the incident response itself
- Minimize manual transcription between Slack and Jira
When post-incident reviews are grounded in what actually happened rather than what is remembered afterward, they become faster, more accurate, and easier for engineers to engage with.
How Phoenix Incidents Supports a Better PIR Process
Phoenix Incidents is designed to make the post-incident review process more structured, accurate, and actionable in tools like Jira and Slack. Unlike traditional approaches that rely on multiple disconnected tools, Phoenix Incidents anchors the entire incident lifecycle in familiar workflows, reducing cognitive load and friction for engineering teams.
When it comes to post-incident reviews, Phoenix Incidents provides structured guidance at every step. It helps teams reconstruct timelines accurately from Slack and Jira activity, capture contributing themes consistently, and generate concrete, time-bound action items.
Action items are enforced with Slack reminders, ensuring follow-through, which is often the biggest gap in traditional PIRs. A key differentiator is Phoenix Incidents’ treatment of canceled incidents. Teams are encouraged to raise incidents without fear of false alarms, and canceled incidents are tracked with required reasons.
This allows teams to systematically review these cases and identify training gaps or alerting issues, and continuously improve the escalation process. This approach formalizes a best practice that many teams discuss but rarely execute effectively in their PIRs.
Conclusion
By combining structured PIR guidance, timeline reconstruction, thematic analysis, and follow-up enforcement, Phoenix Incidents transforms the post incident review from a reactive reporting exercise into a proactive improvement mechanism. Teams and leadership can clearly see what broke, why it broke, and whether the actions they agreed on are being completed, all without leaving Jira or Slack.
If your post-incident reviews feel inconsistent, forgotten, or disconnected from real incident work, it may be time to anchor them where incidents actually happen. Try Phoenix Incidents to see how teams run better post-incident reviews directly inside Jira and Slack without adding another tool.