Context Switching: Why It Slows Incident Resolution and How to Fix It


Most incident calls don’t fall apart because the engineers don’t know what they’re doing. They fall apart because everyone is chasing context at the same time, jumping between Slack, Jira, paging tools, dashboards, and documents just to figure out what’s actually happening. This is true for the engineers solving the problem, customer-facing teams trying to help your customers, and leadership trying to get a handle on the situation.
In the first few minutes of an incident, that scramble adds up fast. Updates live in different places. Status drifts. Someone is always asking, “What’s the latest?” It’s not dramatic, but it’s expensive. And most teams quietly accept it as normal.
Research backs this up. Even short bursts of context switching can consume a large portion of productive time. When that loss shows up during an outage, it compounds into slower recovery, missed updates, and unnecessary stress for everyone involved (APA).
This article looks at how context switching shows up during incidents, why it gets worse under pressure, and what engineering teams can actually do to reduce it, without adding yet another standalone tool to the mix.
We’ll also show how teams using Phoenix Incidents reduce unnecessary tool hopping by keeping incident coordination inside Jira and Slack, while continuing to work with their existing paging systems.
What Is Context Switching (For Engineering Teams)?
Context switching is the act of rapidly shifting attention between tools, tasks, or mental models. During an incident, this cost rises because the stakes (and cognitive load) are higher.
Context switching examples in engineering incidents include:
- Checking Slack, Teams or Zoom for updates
- Opening Jira to update the incident status
- Jumping into your paging system to see who’s on-call
- Responding to stakeholders about the incident status
- Checking dashboards, APM systems and logs
- Reviewing recent deployments and environment changes
Engineers have to do all the above while trying to solve the incident.
Each switch interrupts the flow, delays communication, and increases the likelihood of missed details.
Why Context Switching Gets Worse During Incidents
Higher Cognitive Load
During an outage, engineers must:
- Diagnose unfamiliar failure modes
- Coordinate across teams
- Track customer impact
- Manage SLAs
- Communicate clearly
Adding tool switching on top of that drastically weakens focus during incident response.
Increased Communication Surface Area
Incident communication workflows rarely live in one place. Without structure, responders may check:
- Emails
- Slack or Teams channels
- Jira
- A standalone incident tool
- Telemetry & Logging alerts
- Paging alerts
The more communication tools a team uses, the harder it is to track what’s happening.
Tool Fragmentation
Many organizations patch together several systems to respond to incidents:
- Real-time coordination (Slack, Teams, etc)
- Issue Tracking (Jira, Linear, etc)
- Paging systems (Splunk, PagerDuty, OpsGenie, etc)
- Document systems for RCAs (Google Docs, Confluence, etc)
None of these systems is the problem individually. The friction comes from switching among them continuously with no connective workflow in a large team.
Phoenix Incidents reduces this by living inside where your team already work and talks (Slack and Jira), integrating with paging tools where needed, and removing the need to swivel-chair across multiple dashboards.
How Context Switching Impacts Incident Response Outcomes
Every extra minute spent chasing updates during an incident compounds into real business cost, slower recovery, frustrated customers, and wasted engineering time. For leadership, context switching isn’t a usability issue. It’s a reliability issue, and it has a direct impact on how fast the organization can recover when something breaks.
When incidents drag because teams are context-saturated—leadership effectively pays a hidden tax: more engineer-hours per outage, slower customer recovery, and delayed product delivery elsewhere in the roadmap. This shows up as real customer pain and real lost revenue (an Oxford Economics study estimated that downtime costs an organization an average of $9,000 per minute).
Cognitive (Over)Load
There’s also a quieter cost on the people in the middle of it. Engineers spend those minutes juggling tabs, chasing updates, and trying not to miss something important while everything is already under pressure. That cognitive load doesn’t show up on a dashboard, but it shows up in fatigue, frustration, and slower decisions when clarity matters most.
Slower Alignment
When responders rely on multiple communication surfaces, they spend more time searching for updates and less time responding.
Inconsistent Information
Tool switching can create mismatches in severities, outdated statuses, missing SLA updates, and conflicting notes.
Increased MTTA
Though not a major cause, tool switching creates friction that directly impacts MTTA (Mean Time to Acknowledge). When responders must jump between Slack, Jira, paging tools, and dashboards just to gather context, those extra seconds compound quickly when speed matters most. By keeping incident workflows anchored where engineers are already working, Phoenix Incidents helps reduce the time it takes for teams to acknowledge and begin coordinating around an incident.
Lost Tribal Knowledge
When data lives in multiple tools, assembling post-incident review material becomes a noisy archaeology project. Over time, that wears teams down, slows down RCAs, and makes post-incident reviews feel more like cleanup than learning.
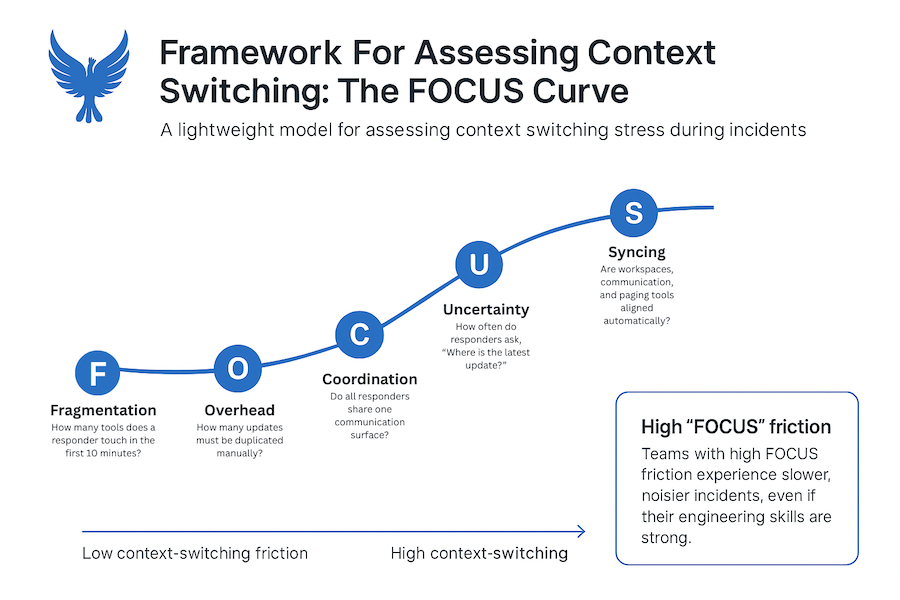
Framework For Accessing Context Switching: The FOCUS Curve
A lightweight model for assessing context switching stress during incidents.
F (Fragmentation): How many tools does a responder touch in the first 10 minutes?
O (Overhead): How many updates must be duplicated manually?
C (Coordination): Do all responders share one communication surface?
U (Uncertainty): How often do responders ask, “Where is the latest update?”
S (Syncing): Are workspaces, communication, and paging tools aligned automatically?
Teams with high FOCUS friction don’t run worse incidents because they lack talent—the noise just gets in their way.
How Phoenix Incidents Reduce Context Switching
Phoenix Incidents is designed specifically to reduce unnecessary tool switching tool switching during incidents by anchoring every phase inside Slack and Jira.
1. Human-Initiated Creation Directly in Slack or Jira
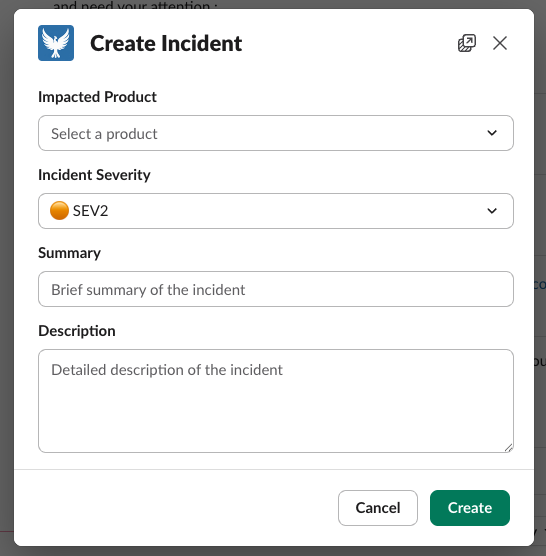
No need to switch platforms when an incident is confirmed; incident resolution starts where engineers already operate. When an incident occurs, Phoenix Incidents eliminates the first context switch.
If in Jira, engineers can directly create an incident in Jira with our Jira-native tool available in Atlassian Marketplace, no need to open a separate tool or navigate away from the ticket they're already triaging.
In Slack, responders can create an incident with a slash command (/phoenix) right in the channel where the problem is being discussed.
This means the very first step (acknowledging and escalating the incident) happens exactly where the team is already working, without forcing anyone to leave their current context or remember to log into another platform.
2. Real-Time Communication in Shared Slack Channels
Phoenix Incidents creates dedicated Slack channels for each incident once the incident has been escalated or created. All responders see a consistent, synced status without bouncing to Jira.
3. Status Synchronization
Any change made in Jira automatically updates Slack and your paging system. And vice-versa. No duplicating work. No copying status messages.
4. SLA-Based Reminders
Phoenix Incidents reminds responders directly in Slack each step of the way in an incident, from posting regular updates to keeping the team on track to acknowledge or verify an incident.
5. Guided Root Cause Analysis
After the resolution, Phoenix Incidents provides an intelligent, guided RCA tool with thematic tagging, and action item collection.
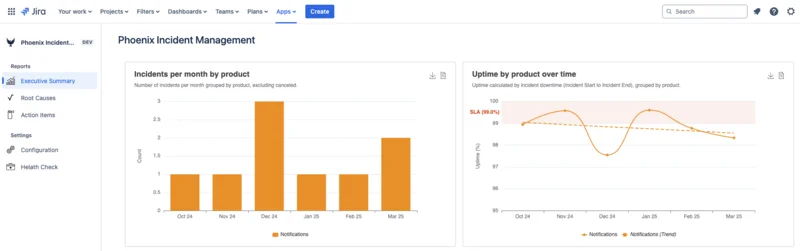
6. Dashboards That Don’t Require a New Tool
Phoenix Incidents reports on: MTTA, MTTR, Uptime, SLA performance, recurring themes, overdue action items and more.
All this within Jira—no separate reporting application required.
Incident Management Without Context Switching:
| Before Phoenix Incidents | After Phoenix Incidents |
|---|---|
| Slack threads everywhere | Single Slack channel per incident |
| Jira out of sync | Jira + Slack automatically aligned |
| Manual copying between tools | No app-hopping |
| Missed SLAs | Clear SLA reminders |
| Responders asking "Where is the latest?" | One visible source of truth |
| High cognitive load | Structure without extra tools |
| Inconsistent RCAs | Guided RCA with themes and action items |
| Multiple tools open just to track status | Leaders get visibility without chasing updates |
If you answer ‘yes’ to 3 or more of these, your team is likely being slowed down by context switching—and you may not even realize it yet:
- We use at least 4 tools during the first 10 minutes of an incident
- SLAs are missed because updates aren’t tracked consistently
- Our communication and workspace tools statuses and updates rarely match
- Responders often ask, “Where is the source of truth?”
- RCAs take too long to produce
- Leaders can’t easily see recurring patterns or overdue mitigations
Conclusion
Context switching is one of those things teams normalize without realizing how much it’s slowing everything down, especially during incidents. Most teams already have plenty of tools. The real problem is how disconnected they become the moment an incident starts. They need clearer workflows and incident management that lives where they already work.
As organizations scale, this coordination tax only grows: more teams + more tools equals more hand-offs. Without a system that standardizes how incidents run, leadership loses visibility and predictability exactly when it matters most.
If incident response feels harder than it should, it usually is. Book a demo and see what it looks like when coordination stops getting in the way.