Incident KPI Best Practices: Metrics That Drive Faster Resolution And Recovery


Once an incident is resolved and everything returns to normal, how do you know if you're actually improving at handling incidents? The answer lies in tracking the right incident KPI.
Incident management KPIs are more than vanity metrics on a dashboard. They reveal patterns in how your team detects, responds to, and resolves critical outages. More importantly, they expose whether you're addressing root causes or you are just playing around with the same issues quarter after quarter. Here we’ll discuss:
- The most important incident management KPIs
- Practical incident management KPI examples
- How good teams use major incident KPIs without burning out engineers
- Where tooling often breaks down and what to look for instead
What Is An Incident KPI?
An incident KPI is a signal about how effectively your organization handles production incidents. Not how fast someone typed “resolved,” but how well teams detected issues, coordinated response, communicated impact, and learned afterward.
A great incident management KPI reinforces good operational behavior. Weak ones encourage silence, delay, or burnout. A useful mental model is this: if a KPI makes post-incident learning feel optional or performative, it’s not pulling its weight
This distinction matters because the goal of incident metrics is not to prove competence. It's to help you spot problems so you can fix them in a clear, organized way.
Detection Is Not Incident Management
Before discussing these metrics, it’s essential to distinguish between detection and response. Mean Time to Detect (MTTD) is often lumped into incident management KPIs. Still, detection is driven by observability tooling, such as Datadog, New Relic, and Sentry, rather than incident response platforms. Weak MTTD typically indicates gaps in monitoring coverage or alert quality, rather than human process. That’s why most incident management KPI examples start after an alert exists and a human needs to respond. Now, let’s look into these metrics.
1. MTTA
Mean Time to Acknowledge (MTTA) measures how long it takes for a human to acknowledge an alert after it’s generated. While MTTA is technically part of MTTR, its value is diagnostic rather than outcome-driven. When MTTA is high or inconsistent, it often signals alert fatigue, unclear ownership, or a lack of psychological safety around escalation. Teams hesitate because they don’t know whether they’re “allowed” to declare an incident. Reducing MTTA slightly does not magically reduce overall resolution time, but persistently poor MTTA is a warning sign that incident response will struggle under real pressure.
2. MTTR
Mean Time to Recovery (MTTR) is the most widely tracked major incident KPI and the most abused. Leadership loves MTTR because it’s simple. Engineers tend to dislike it because it flattens complex situations into a single number. MTTR makes teams close incidents quickly (which can be a good goal). When used responsibly, MTTR helps teams understand whether response effectiveness is improving over time within the same system or service. MTTR is not a performance score. It helps change behavior.
3. Communication KPI
Teams that track whether updates were sent on time, whether stakeholders were informed, and whether a clear incident lead was established tend to run calmer incidents. These KPIs don’t measure speed; they measure coordination. The challenge is that communication metrics fall apart when updates must be manually synchronized across messaging tools like Team and Slack, Jira, and paging systems. During high-stress incidents, engineers will always prioritize fixing the issue over updating different tools. Any KPI that depends on memory will degrade over time.
4. Post Incident Reviews
Many organizations claim to value learning from incidents, but their metrics say otherwise. A simple but powerful incident management KPI is the Post Incident Review (PIR) completion rate. If PIRs routinely don’t happen, or happen weeks later, it’s usually because the process is too heavy or disconnected from daily work. What matters more than the document itself is whether the review produces concrete action items with owners and timelines. Tracking overdue action items is one of the few leading indicators that an organization is actually reducing future risk. This is also where language matters. Treating outcomes as “tasks” turns learning into chores. Treating them as action items reinforces accountability without blame.
5. Canceled Incidents
One of the clearest signals of a healthy incident culture is how a team handles incidents that didn’t need to be incidents. A canceled incident represents a healthy escalation that turned out not to require a full response. High-performing organizations encourage these. They do not punish them. They also do not ignore them. High-performing engineering teams track canceled incidents, require a cancellation reason, and review them periodically. Many organizations say they value this practice. Very few formalize it.
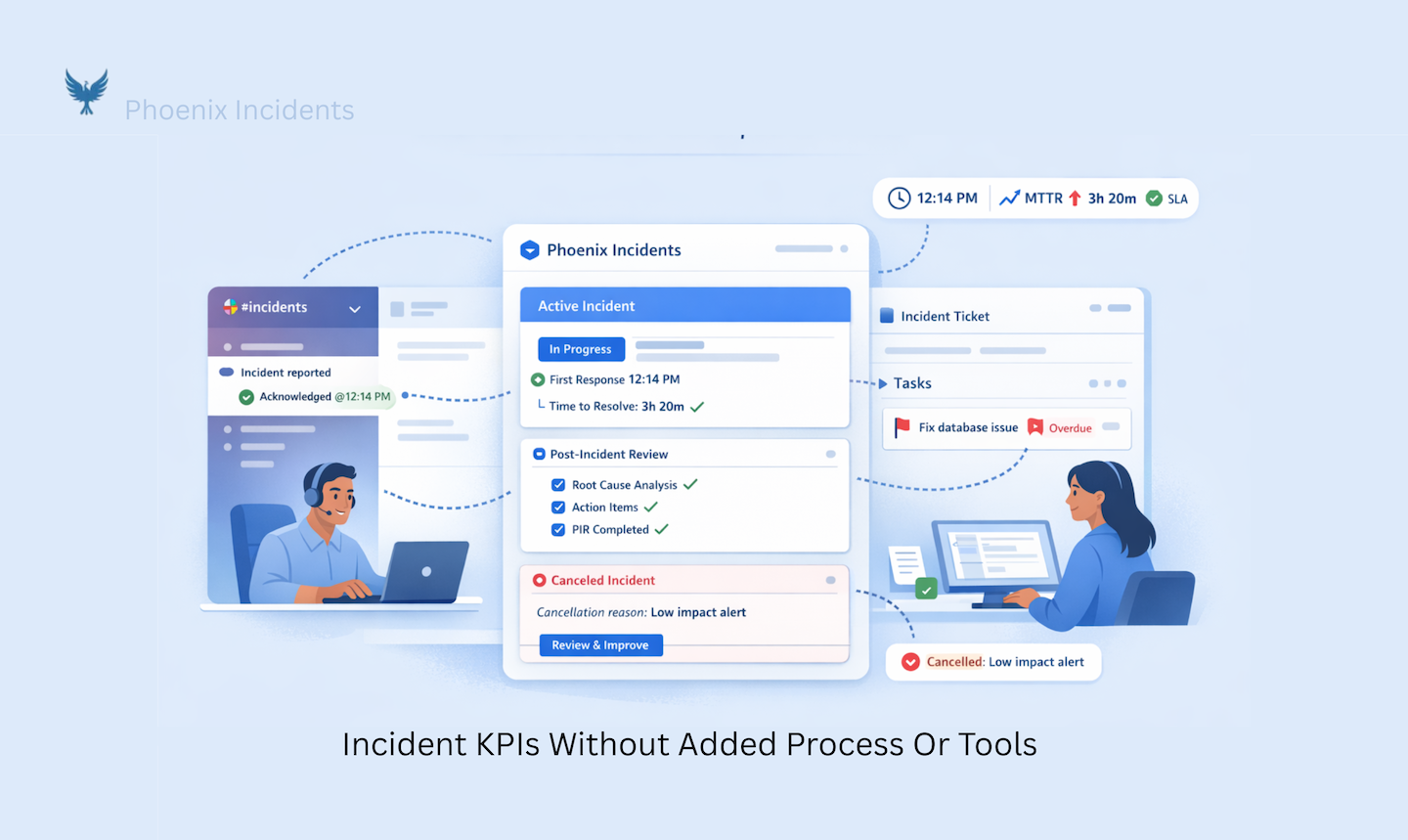
How Phoenix Incidents Supports Incident KPIs
Phoenix Incidents is designed around the reality that incidents already live in Jira and Slack. Rather than introducing a separate system, it enforces a clear incident workflow directly inside those tools.
Incident KPIs like MTTA, MTTR, SLA adherence, PIR completion, and overdue action items emerge naturally from the process. Slack channels stay in sync with Jira. Paging systems like PagerDuty and VictorOps are integrated so engineers don’t have to context-switch, but Phoenix Incidents does not replace or modify alerting.
Phoenix also embeds canceled incidents as a first-class concept, requiring teams to record why an incident was canceled and making those patterns reviewable over time. This supports early escalation without punishment, something many teams want culturally but struggle to support operationally. The goal is not faster heroics. It’s fewer repeat incidents, calmer responses, and learning that actually sticks.
Choosing Incident KPIs That Actually Improve Reliability
Before introducing a new incident KPI, engineering leaders should ask a simple question: Will this metric make it easier for teams to do the right thing during an incident? If the answer is no, it’s probably not worth tracking. The best incident management KPIs encourage early escalation, reinforce clear communication, and make learning unavoidable but not painful. When those conditions are met, the metrics stop being controversial and start being useful.
Conclusion
Every incident KPI sends a message. It tells engineers what behavior is rewarded, tolerated, or ignored. When chosen carefully and supported by the right workflow, incident KPIs become a stabilizing force rather than a source of stress. They help leaders see what’s breaking, why it’s breaking, and whether the organization is actually fixing the underlying problems.
That’s the difference between measuring incidents and managing them. If you want incident KPIs that reflect how incidents actually happen, without adding another tool or more process overhead, book a demo of Phoenix Incidents and see how teams manage incidents, reviews, and metrics directly inside Jira and Slack.
If you want a free setup up you can start with today (DIY), the full details on how to build this are in the guide linked at the bottom. Get the Full Setup Guide.
Our team used this when we were just starting.