How to Improve MTTR Without Burning Out Your Engineering Team

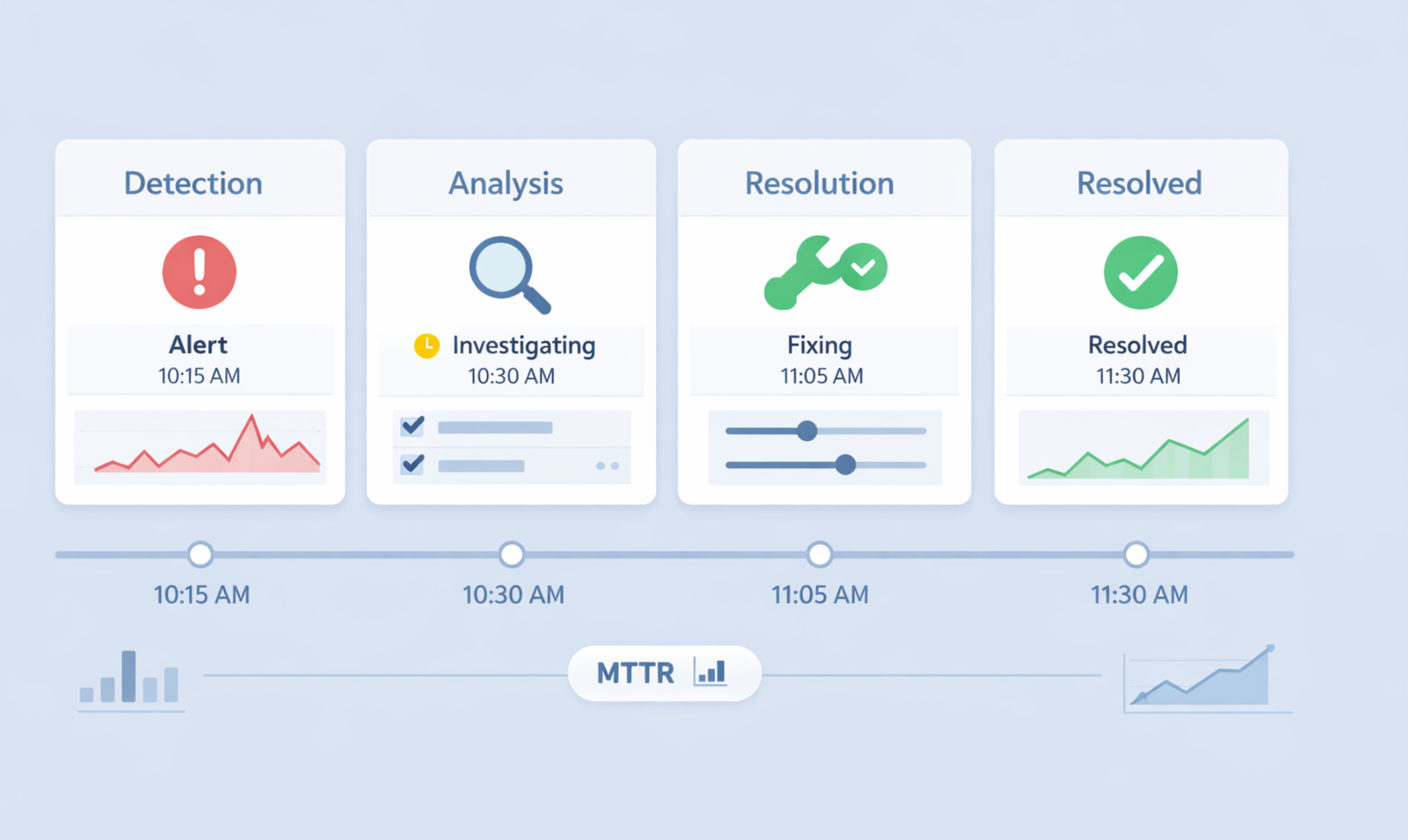
Every engineering leader knows MTTR matters. Mean Time to Resolution is tied directly to customer trust, revenue protection, and team health. Yet even mature organizations struggle with how to improve MTTR in practice, especially as systems become more distributed and teams grow.
The challenge is rarely a lack of good talent or effort; it’s friction. During serious customer-impacting production incidents, engineers must juggle multiple manual incident processes while simultaneously diagnosing and resolving the issue. Improving MTTR requires more than faster alerts; it requires reducing cognitive and procedural load during incidents.
Let’s talk about realistic ways to improve MTTR using automation, observability, and disciplined incident workflows.
What Does MTTR Measure?
MTTR (Mean Time to Recovery) measures how long it takes from when a problem starts until it's fixed. It usually includes several steps:
- Detection (often tracked separately as MTTD).
- Acknowledgement (MTTA).
- Triage and diagnosis.
- Mitigation and recovery.
- Communication and coordination.
Common Reasons MTTR Stays High
Before discussing solutions, it’s worth naming the most common contributors to prolonged MTTR in real-world engineering teams:
- Procedural Overload During Incidents: Engineers aren't just fixing the problem. They're also creating Jira tickets, communicating with multiple stakeholders, paging the right people, updating leadership and support teams, and trying to remember all the process steps while under pressure. None of this actually solves the issue, but it takes up a lot of mental energy.
- Fragmented Communication: Information gets spread out across different places which makes it harder to keep track of what's happening and can cause important details to be missed or delayed. Important context may be lost, duplicated, or delayed.
- Fear of Escalation: Teams often wait too long to call an incident because they're worried about raising a false alarm or being called out for overreacting. This delay makes the problem worse and increases the time it takes to fix things.
- Inconsistent Follow-Through After Incidents: Teams often rush through or skip Post Incident Reviews, which means the same problems keep coming back, important action items get forgotten, and the underlying causes are never truly fixed.
How to Improve MTTR With Observability
Observability tools such as Datadog, New Relic, and Sentry help improve MTTR by reducing detection time and accelerating diagnosis. Here's how:
Faster Detection (Reducing MTTD):
- Real-time monitoring surfaces anomalies before users report issues.
- Intelligent alerting cuts through noise by correlating related signals into a single alert.
- Distributed tracing helps teams spot cascading failures across services immediately.
Faster Diagnosis:
- Unified dashboards provide full-stack visibility (logs, metrics, traces) in one place, reducing time spent context-switching between tools.
- Pre-built integrations automatically correlate errors with deployments, infrastructure changes, or dependency failures.
- Detailed error context (stack traces, request IDs, user sessions) helps engineers pinpoint root causes without guessing.
Better Incident Context:
- Historical data and trend analysis help teams understand if an issue is recurring or new.
- Custom metrics and service-level indicators (SLIs) make it clear when systems are degrading before they fail completely.
These capabilities directly improve the detection and diagnosis phases of MTTR. However, observability tools don't manage incident coordination, ensure process consistency, track follow-through on action items, or prevent the same incidents from recurring.
This is where teams often stall. They invest heavily to improve MTTR with observability, but see diminishing returns because the bottleneck has shifted from detection to incident execution and follow-through.
How to Improve MTTR With Automation
If observability tells you what's broken, automation is what keeps incident response from breaking down. This is where most teams can improve MTTR, because automation directly addresses the execution and follow-through bottleneck that observability doesn’t solve directly.
When teams think about automation and MTTR, they usually only think about automatically fixing problems (auto-remediation). But in practice, procedural automation delivers more consistent, measurable impact on MTTR. Here's how:
Reducing Coordination Overhead:
- Automatically create incident records the moment someone escalates, eliminating manual ticket creation during critical moments.
- Keep Jira, Slack, and paging tools synchronized in real time so no one wastes time hunting for the latest status.
- Auto-provision dedicated incident channels so communication stays organized from the start.
Enforcing Process Consistency:
- Guide responders through each phase of the incident lifecycle with workflow prompts, removing reliance on memory during high-stress situations.
- Send SLA-based reminders for status updates, escalations, and next steps so incidents don't stall waiting for someone to remember what's next.
- Standardize severity classification and response workflows so every incident follows the same playbook.
Driving Follow-Through:
- Automatically trigger Post-Incident Review (PIR) creation when incidents close.
- Track action items to completion with proactive reminders, preventing the "resolve and forget" pattern that leads to recurring incidents.
- Link action items back to the original incident for full traceability.
This type of automation doesn't "fix" the technical problem, but it removes the procedural friction that inflates MTTR. Phoenix Incidents lives entirely inside Jira and Slack, automating the coordination and process overhead that slows teams down during high-severity incidents. Engineers don't need to context-switch to yet another tool while production is on fire.
How to Improve MTTR With Disciplined Incident Process
Observability surfaces the problem, automation reduces coordination overhead, but discipline throughout the process is what prevents MTTR from increasing. Most teams don't realize how much time they lose to process chaos until they measure it.
Here's how disciplined incident workflows directly improve MTTR:
Eliminating Decision Fatigue:
- Set clear severity levels ahead of time so teams don't waste time deciding how serious an incident is.
- Know exactly who to contact for help so no one has to figure it out during an emergency.
- Use ready-made update messages so teams can quickly inform others without thinking about what to say.
Preventing Critical Gaps:
- Clear step-by-step workflows make sure teams don't forget important tasks like acknowledging the incident, sharing updates, or keeping stakeholders informed.
- Required handoff checklists help capture important details when the on-call person changes during an incident.
- Automatic Post-Incident Review reminders make sure teams actually learn from incidents instead of just fixing them and moving on.
Creating Predictability Under Pressure:
- When teams follow the same steps every time, they build habits that make it easier to respond quickly even under pressure.
- Having one central place for all incident updates saves time because teams don't have to search through multiple tools to find information.
- Automatic reminders help keep things moving so incidents don't get stuck waiting for someone to remember the next step.
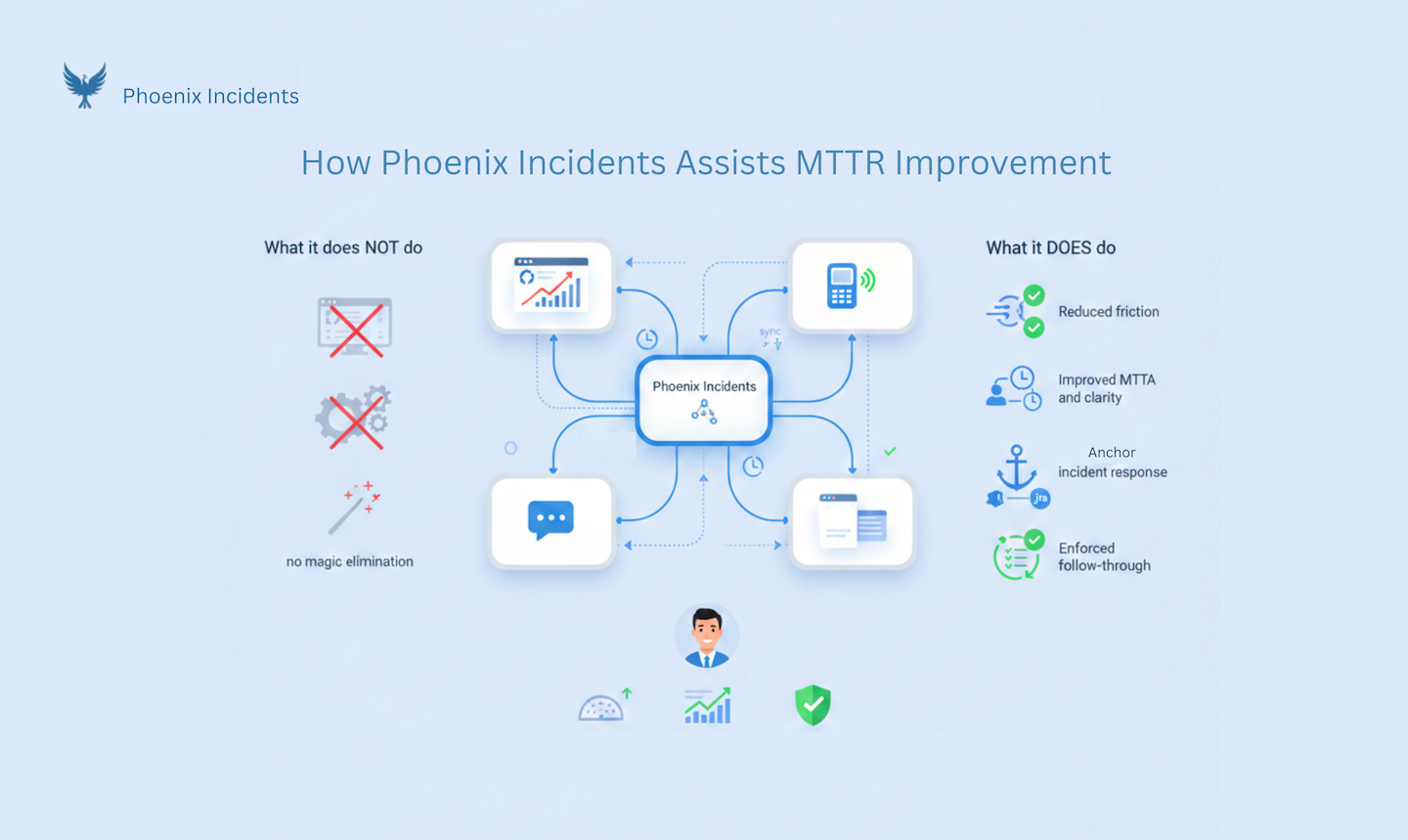
How Phoenix Incidents Fit Into MTTR Improvement
Phoenix Incidents doesn't replace your monitoring tools or paging systems. What it does is take away the extra work that slows teams down during incidents. It helps teams respond a bit faster by making things clearer and easier to coordinate. It keeps all your incident work organized in Jira and Slack, where your team already works. And it makes sure you actually follow through on fixing problems so the same incidents don't keep happening. For engineering leaders, this means less chaos during incidents, better information about what's going wrong, and more confidence that your team is solving real problems instead of just putting out fires over and over.
Conclusion
If you’re searching for ways to improve MTTR, the answer isn’t another dashboard or alert. It’s removing the hidden friction that slows teams down during the worst moments of engineering. Observability helps you see problems, while automation helps you move faster, but disciplined incident workflows are what prevent chaos from inflating your response times. Click the button below to request a no-pressure demo on how Phoenix Incidents helps engineering teams coordinate serious production incidents—inside Jira and Slack.
If you want a free setup up you can start with today (DIY), the full details on how to build this are in the guide linked at the bottom. Get the Full Setup Guide.
Our team used this when we were just starting.