6 Engineering Incident Management Best Practices


Most engineering teams know what they should do during an incident. They know they should escalate early, keep a clean timeline, and run a blameless PIR (these are standard Incident management best practices.) The problem isn't a lack of knowledge; it’s the procedural friction of actually doing it while the site is down.
For SRE and DevOps teams, this means less guesswork and fewer missed updates. Phoenix Incidents embeds these practices directly inside Jira and Slack, so procedural overhead doesn't slow down the actual work of restoring services.
Here are six best practices that separate teams who manage incidents consistently from teams who improvise every time and what it looks like to embed each one into your team's workflow.
DON'T MISS: How You Can Build Incident Management Inside Jira For FreeSix Best Practices to Improve Incident Management

1. Lower the Barrier to Entry
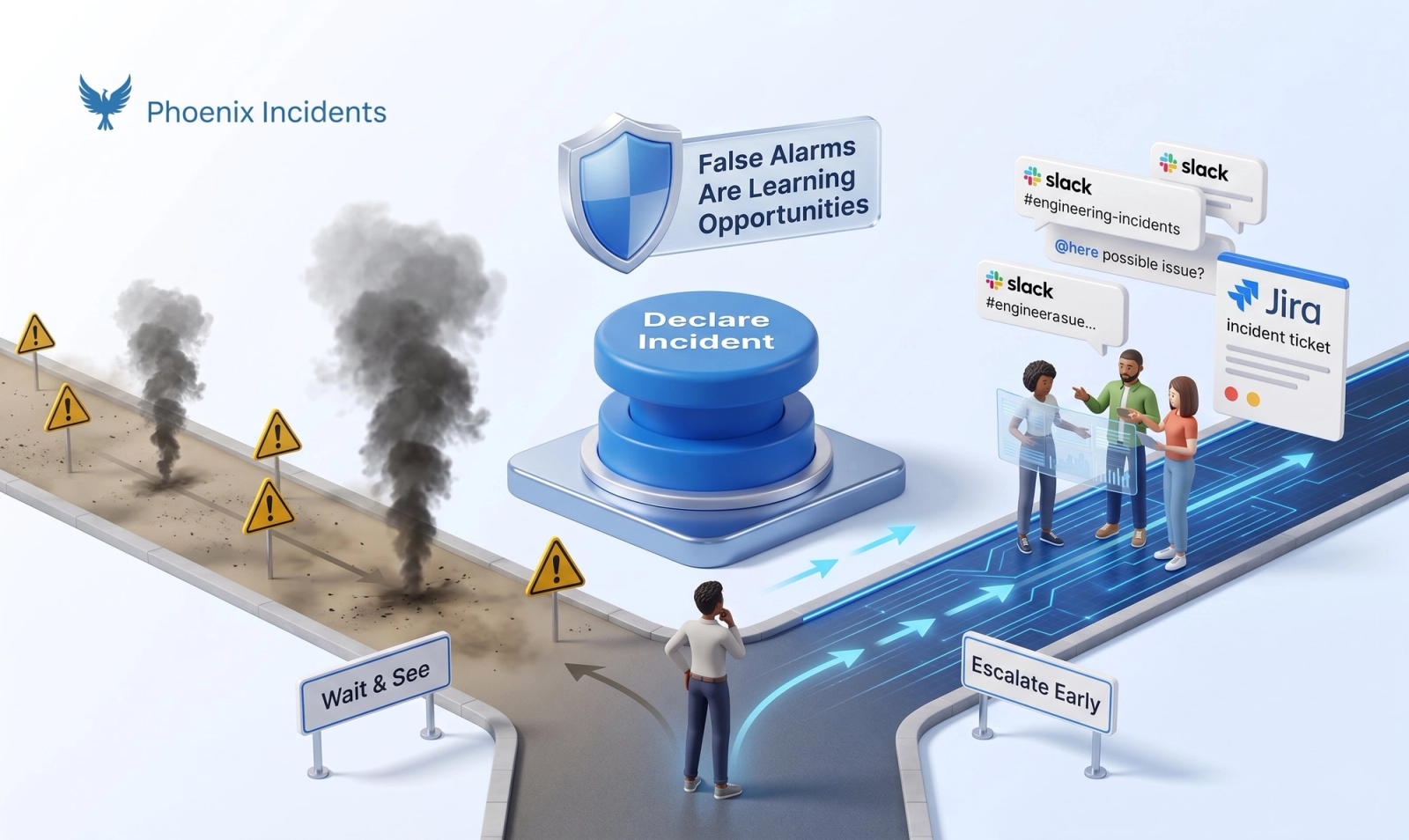
Most incident response problems start before the incident is even declared. Engineers and customer-facing teams often wait too long to pull the fire alarm. They worry about "crying wolf" or looking foolish if the issue turns out to be minor. Customer support teams that have been criticized for raising false alarms may hesitate to escalate. And on-call engineers sometimes avoid declaring incidents to escape the tracking, oversight, and scrutiny that comes with formal incident management.. This hesitation is where SEV1s are born.
A best practice isn't just a definition; it's a culture that makes declaring an incident lower risk than waiting. When teams agree on what qualifies (customer impact, service degradation, security risk, or operational uncertainty), the decision to escalate becomes less personal and more procedural. The definition decides, not the individual's fear of judgment. We treat a canceled incident as a win for the system, not a waste of time.
Phoenix Incidents makes incident creation deliberate and human-initiated inside Jira or Slack. Unlike systems that automatically create incidents from alerts, Phoenix Incidents requires human judgment to declare an incident.
This is intentional: alerts signal potential problems, but incidents require coordination, communication, and response. Not every alert deserves the overhead of incident management, and not every incident starts with an alert. By requiring human intervention, we ensure that incidents are declared when the risk is real enough to warrant coordination and response, not just when a threshold is crossed. When the definition is shared and visible, escalation becomes faster and less personal.
2. Build a Workflow that Runs End-to-End
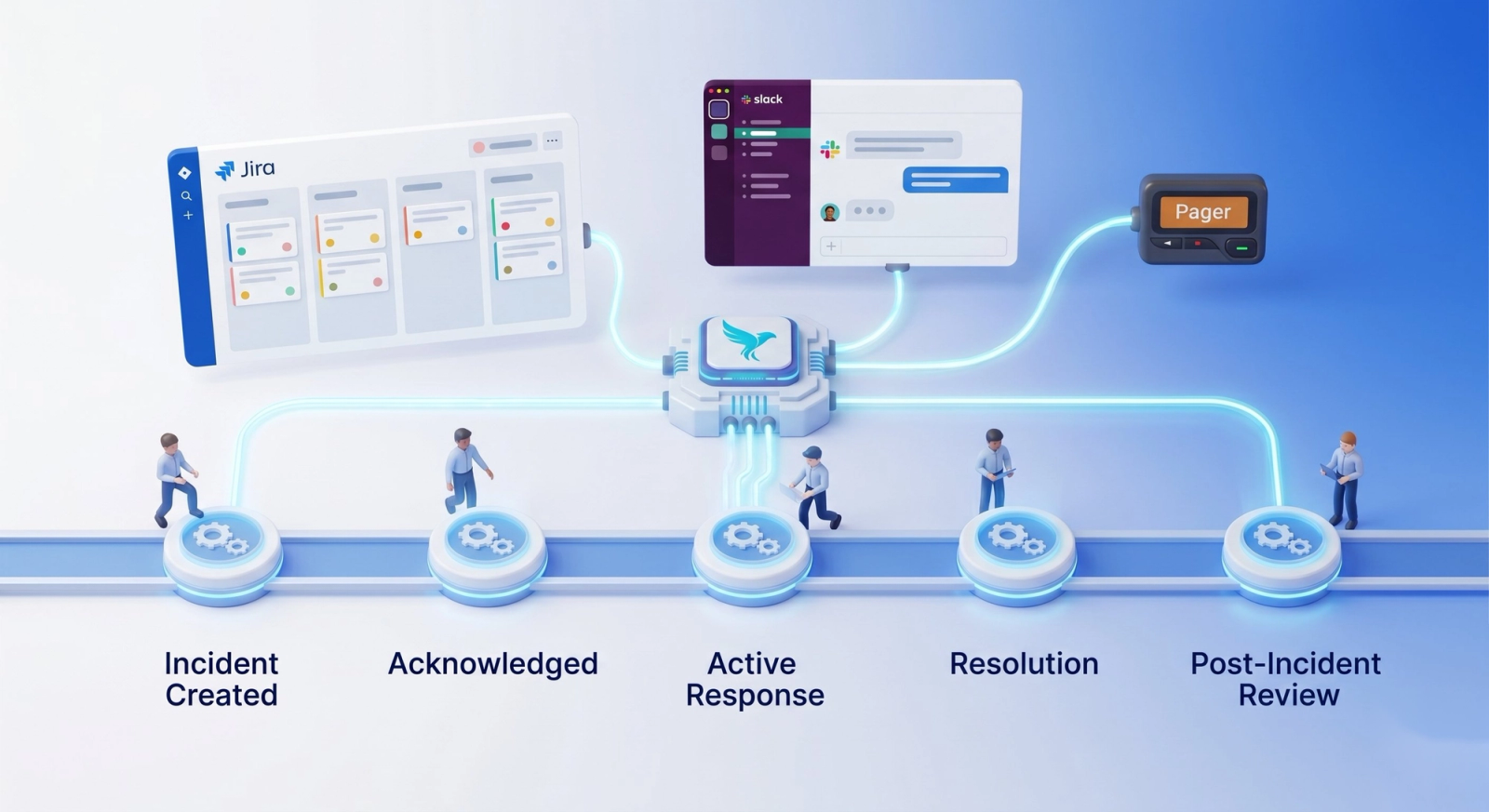
Without a defined workflow, incident response turns into improvisation. Updates get lost, Jira drifts out of sync with Slack, and engineers burn time managing the process instead of restoring service.
A structured workflow follows a clear sequence:
- Incident creation
- Acknowledgment
- Active response and coordination
- Resolution
- Post Incident Review (PIR)
Phoenix Incidents enforces this flow. Jira, Slack, and paging integrations stay aligned so the workflow doesn't fracture across systems. SLA-based reminders keep things moving without manual chasing.
The value isn't speed, it's predictability. Everyone knows what happens next.
3. Make Roles and Responsibilities Explicit
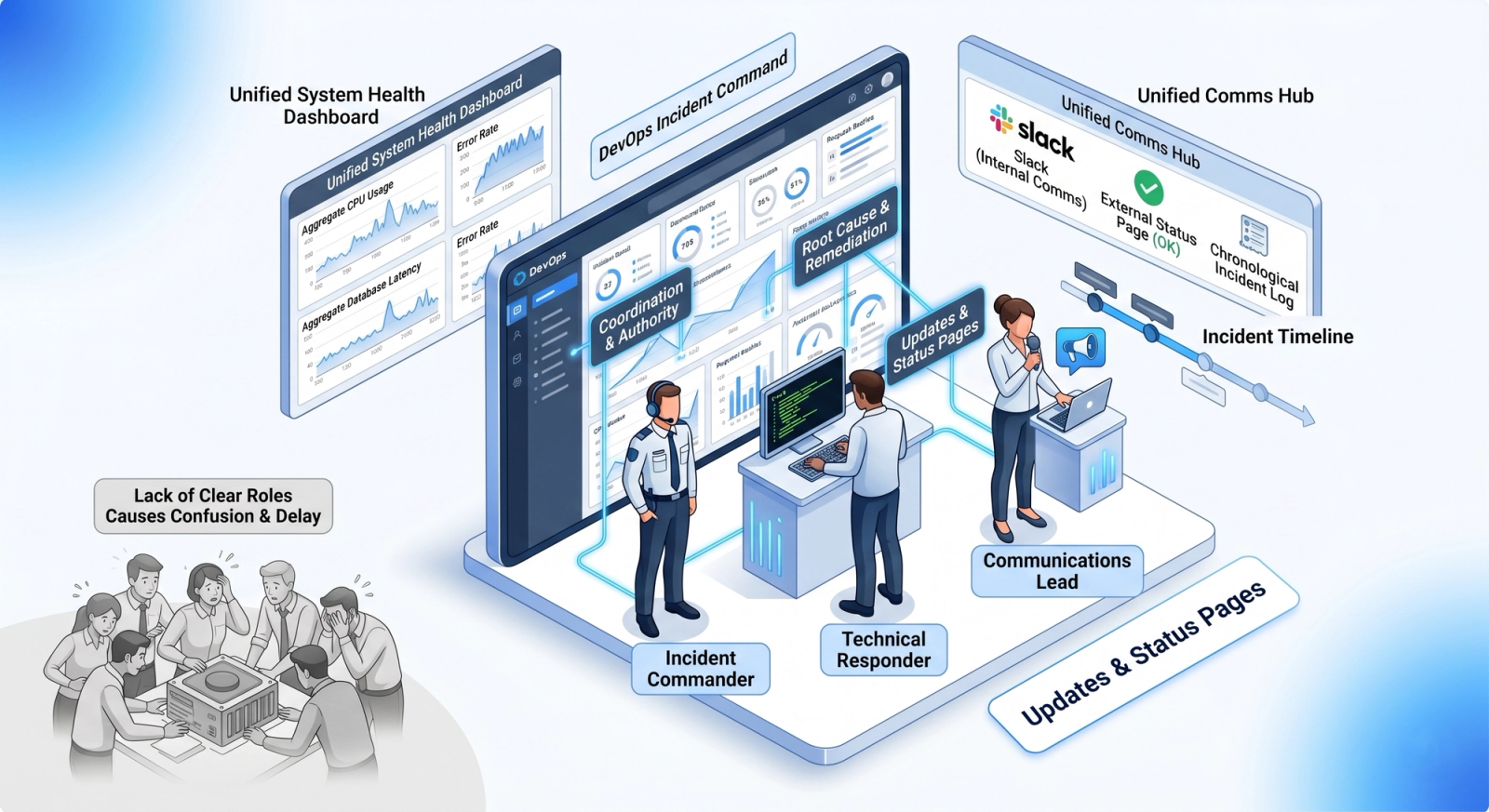
In the middle of an incident, ambiguity compounds stress. Two people assume someone else is updating stakeholders. Five people jump into debugging the same thing. Important decisions get delayed because no one knows who owns them.
Clear roles remove that friction. Incident leadership, technical responders, and communication owners don't need to be rigid titles, but they do need to be explicit.
Phoenix Incidents makes ownership visible by tying responsibility to the incident record and centralizing communication in Slack. This prevents the silent failure mode where everyone is working, but no one is coordinating.
When roles are clear, engineers stop stepping on each other and start trusting the process.
4. Kill the "ETA?" Distraction

One of the fastest ways to derail incident response is constant status requests. Engineers get pulled out of debugging to answer the same questions repeatedly, often in different channels.
Effective incident management separates doing the work from communicating the state of the work. Stakeholders don't need every detail; they need timely, consistent updates they can trust.
Phoenix Incidents keeps Jira and Slack in sync, so updates made once are reflected everywhere they matter. This reduces cognitive load on responders while giving leadership and customer-facing teams the visibility they need.
The result isn't fewer questions, it's fewer interruptions.
5. Weaponize Your False Alarms
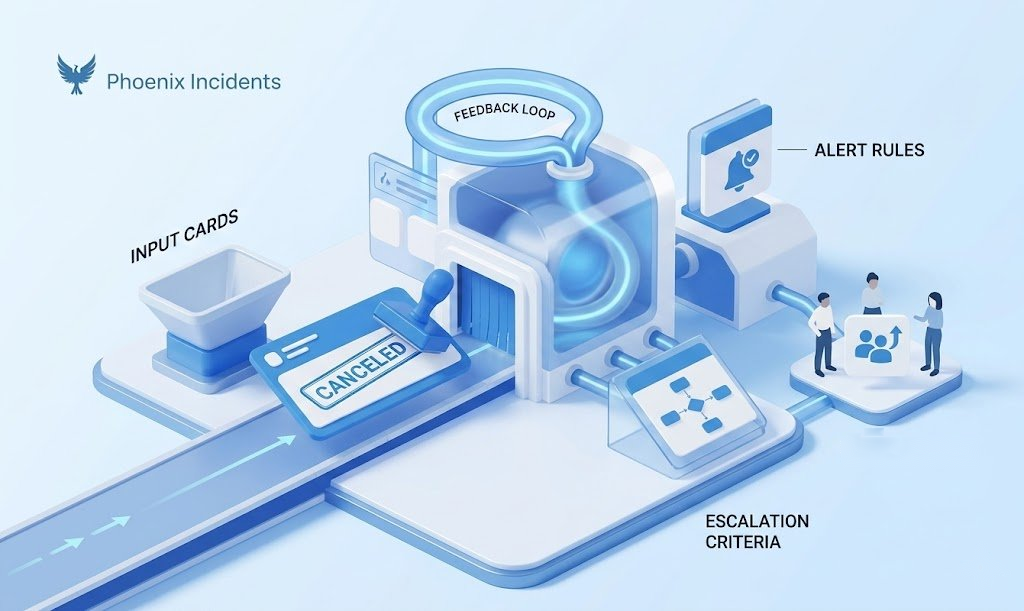
Early escalation only happens when engineers believe they won't be punished for being wrong. If the cost of a false alarm is embarrassment or scrutiny, people wait. And waiting is how small issues become outages.
Canceled incidents are critical but often ignored. Phoenix Incidents embeds them directly into the workflow and requires a cancellation reason. This does two things at once:
- It makes raising incidents psychologically safe.
- It creates structured data for learning.
These canceled incidents get reviewed, not to assign blame, but to tune alerting, escalation criteria, and training gaps. This turns false alarms into one of the most valuable feedback loops in the system.
6. Review, Report, and Learn Through Blameless Post Incident Review
Incidents don't end at resolution. Without a structured review, teams move on quickly and repeat the same failures later.
Blameless post-incident reviews (PIRs) are where learning happens. Not an abstract "what went wrong" concrete understanding:
- What happened, in what order
- Where decisions were delayed or unclear
- What systemic issues made the incident harder to manage
Phoenix Incidents guides PIRs with timeline building, root-cause themes, and time-bound action items. Those action items don't disappear into documents; they're enforced through Slack reminders and visible in dashboards.
This is how practices compound over time: not by avoiding incidents entirely, but by ensuring each one leaves the system stronger.
How These Practices Map to the Incident Lifecycle
| Best Practice | When It Applies | What It Prevents | |||
|---|---|---|---|---|---|
| Lower declaration barrier | Before the incident | Delayed escalation turning small issues into SEV1s | |||
| End-to-end workflow | Throughout | Process improvisation and missed steps | |||
| Explicit roles | Incident start | Coordination failures and duplicate work | |||
| Kill the ETA distraction | During response | Cognitive load on responders from status interruptions | |||
| Weaponize false alarms | After cancelled incidents | Alert fatigue and hesitation to escalate | |||
| Blameless PIRs | Post-resolution | Repeat incidents from unresolved root causes |
What People Think vs. What Actually Happens
What people think: "Our team already does all this. We just need better tooling."
What actually happens: Tooling that doesn't embed these practices makes them optional under pressure. When the site is down, the path of least resistance wins. If the workflow doesn't enforce best practices, engineers will skip steps because they're focused on the problem.
This is why the difference between a good incident management practice and one that actually sticks is whether it's embedded in the workflow or left to individual discipline.
How Phoenix Incidents Embeds These Practices
Phoenix Incidents lives inside Jira and Slack, the tools engineering teams already use, so best practices become part of the natural workflow, not a separate process to remember.
- Human-initiated incident declaration (not just automated alerts) preserves judgment while reducing friction
- End-to-end workflow enforcement keeps Jira, Slack, and paging systems aligned
- Role assignment is visible and tied to the incident record
- Automated status updates reduce the ETA distraction without extra effort from responders
- Canceled incident tracking is built into the workflow with required cancellation reasons
For SRE/DevOps teams in Jira that want to improve their incident management practices in 2026, you can book a demo today!
Frequently Asked Questions
1. What are the most important incident management best practices for engineering teams?
The practices that have the highest impact are: lowering the psychological barrier to incident declaration, running end-to-end structured workflows, assigning explicit roles at incident start, and running blameless post-incident reviews after every incident. These address the most common failure modes: delayed escalation, coordination breakdown, and repeat incidents.
2. Why do engineering teams skip post-incident reviews?
Usually because they feel like overhead when everyone is eager to move on. The reviews that get skipped are typically unstructured, blame-adjacent, or not connected to actionable follow-up. Blameless PIRs with specific, assigned action items are far more likely to happen and to make a difference.
3. What's the difference between a post-mortem and a post-incident review?
The terms are often used interchangeably. Post-mortem carries a more forensic connotation; post-incident review (PIR) tends to emphasize forward-looking improvement. Many teams prefer PIR specifically because it signals a learning orientation rather than an investigation.
4. How do you prevent alert fatigue without missing real incidents?
Track and review false alarms systematically instead of ignoring them. Cancelled incidents are a signal, they reveal where alerting thresholds are miscalibrated or where escalation criteria are unclear. Treating them as data rather than failures lets you tune the system over time.
5. What's the role of psychological safety in incident management?
It's foundational. If engineers fear judgment for escalating early or raising a false alarm, they wait. Waiting converts small, recoverable issues into major outages. Blameless culture isn't just a nice-to-have, it's what makes early escalation behaviourally safe enough to happen consistently.